

DMTN-234
RSP identity management design#
Abstract
The identity management, authentication, and authorization component of the Rubin Science Platform is responsible for maintaining a list of authorized users and their associated identity information, authenticating their access to the Science Platform, and determining which services they are permitted to use. This tech note describes the high-level design of that system and summarizes its desired features and capabilities, independent of choice of implementation.
LDM-554 defines the general requirements for the Science Platform. This design generally addresses requirements DMS-LSP-REQ-0007 (Abide by the Data Access Policies), DMS-LSP-REQ-0020 (Authenticated User Access), and DMS-LSP-REQ-0027 (Privacy of User Activities) of that document. Where it addresses other requirements from LDM-554, those sections are marked with the relevant requirement identifiers.
This is not a complete description of everything we want the identity management system to do, only a design for the portions that have been implemented to date. Designs for further components and features will be added to this document as they are completed. For a list of remaining work, see the remaining work section of SQR-069.
Note
This is part of a tech note series on identity management for the Rubin Science Platform. The other two primary documents are DMTN-224, which describes the implementation; and SQR-069, which provides a history and analysis of the decisions underlying the design and implementation. See the references section of DMTN-224 for a complete list of related documents.
Science Platform deployments#
Addresses requirement DMS-LSP-REQ-0032 (Multiple Installations).
There is no single Rubin Science Platform. Instead, there are multiple deployments of the Science Platform at different sites with different users and different configurations. As far as the identity management system is concerned, those configurations vary only in how users authenticate and where identity information about the users (full name, email address, group memberships, etc.) comes from.
There are three supported configurations:
- Federated identity
Users authenticate via an identity federation such as InCommon, normally using the authentication system of their home institution. Google and GitHub are also supported as sources of authentication. Users maintain their own identity information (seeded by information from the identity federation). Science Platform administrators and users themselves create groups and maintain their memberships.
This is the approach used for Science Platform deployments intended to provide services to the general astronomy community according to the Rubin Observatory Data Policy (RDO-013). Users of these facilities may have no specific affiliation with Rubin Observatory other than being data rights holders. Examples include the IDF and possibly other International Data Facilities or Data Access Centers.
- GitHub
All users authenticate via GitHub, and their identity information is obtained from their GitHub profile. Group membership is based on the user’s membership in GitHub organizations and teams.
This approach is used for some internal test, development, and project support deployments of the Science Platform. It is the easiest configuration to deploy quickly without supporting infrastruture, provided that the restriction to GitHub as an authentication system is acceptable.
- Local identity system
Users are directed to a local OpenID Connect identity provider for authentication, and user identity information comes from either that identity provider or from a local LDAP server.
This approach is used for the USDF and other deployments that want to use a local identity management system, usually because they are intended only for Rubin Observatory affiliates or users local to the facility managing the deployment.
Every deployment of the Science Platform is a separate identity and authentication domain (with the possible exception of some closely-linked deployments used for testing and integration). Access to one deployment of the Science Platform does not grant access to a different deployment of the Science Platform. The same person may have different usernames, authentication mechanisms, and identity information in each Science Platform deployment to which they have access. (See DMTN-253, however, which provides a mechanism to authenticate users against a specific deployment of the Science Platform and obtain metadata about those users.)
Required infrastructure#
In order to deploy the Science Platform’s identity management component, the hosting environment for that Science Platform deployment must provide:
A Kubernetes cluster running a recent version of Kubernetes. The Science Platform, including the identity management system, only supports Kubernetes and will not run in any other environment. It is primarily tested against the “regular” channel of Google Kubernetes Engine and may not work on older versions of Kubernetes.
Load balancing and IP allocation for an ingress controller. This will be used by ingress-nginx to allocate its external IP and to receive external traffic. Due to the specific requirements around auth subrequest handling, the Science Platform provides its own ingress controller and cannot use an ingress controller provided by the hosting environment.
A Kubernetes provider of
PersistentVolumestorage. This will be used to store the token data for the Science Platform. If this storage is not persistent, user tokens will be regularly invalidated. The hosting environment should also provide some way for those volumes to be backed up and restored.A PostgreSQL database for internal storage of authentication and authorization data. The Science Platform can deploy an internal PostgreSQL server if necessary, but this internal server should only be used for development and proof-of-concept deployments, not for production.
A Kubernetes networking layer that does
NetworkPolicyenforcement. All of the security features documented in this tech note depend on Kubernetes-level enforcement ofNetworkPolicyresources. If Kubernetes does not enforce these restrictions, any Science Platform service or user notebook will be able to access any service in the Science Platform as any user.
Component overview#
A federated identity deployment of the Science Platform has, at a high level, the following structure for handling authentication and identity management for two Science Platform services. Both services receive user requests, and service A also sends requests to service B. (The deployment would have multiple services, not just two services as shown.)
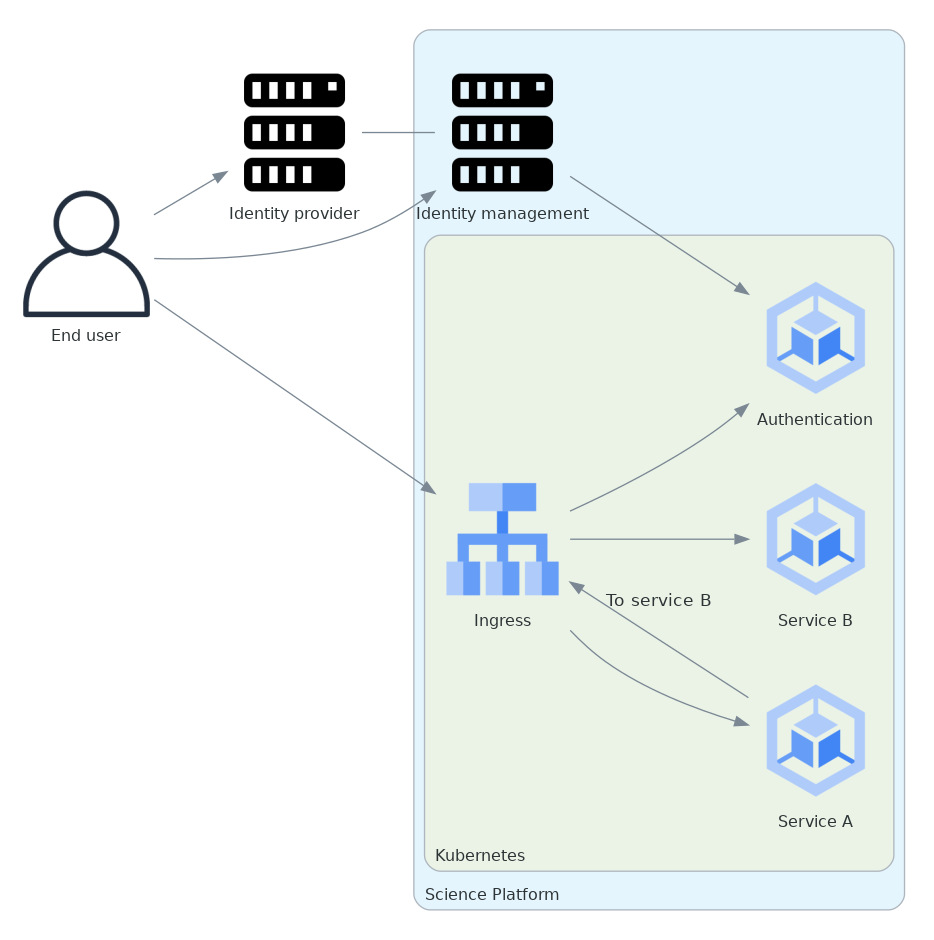
This is a high-level structure of authentication and identity management, using federated identity, for two services that receive user requests. Service A also sends requests to service B.
The identity management component is where the user’s identity data (email, full name, group membership, etc.) and associated identities are stored, and where the user can go to change that information. Here it is shown as running outside of the Kubernetes cluster on which the Science Platform is deployed. This is true in the current implementation but need not be the case in the design.
The Kubernetes ingress verifies authentication and access control on each request with a subquery to the authentication service (labeled Authentication in this diagram).
The diagram for GitHub is similar, except that GitHub serves as both the identity provider and the identity management system.
Local identity management deployments have more variation, since they may or may not use LDAP. Here is a sample diagram for deployment that uses local identity management with an OpenID Connect identity provider and LDAP as the data store for identity information.
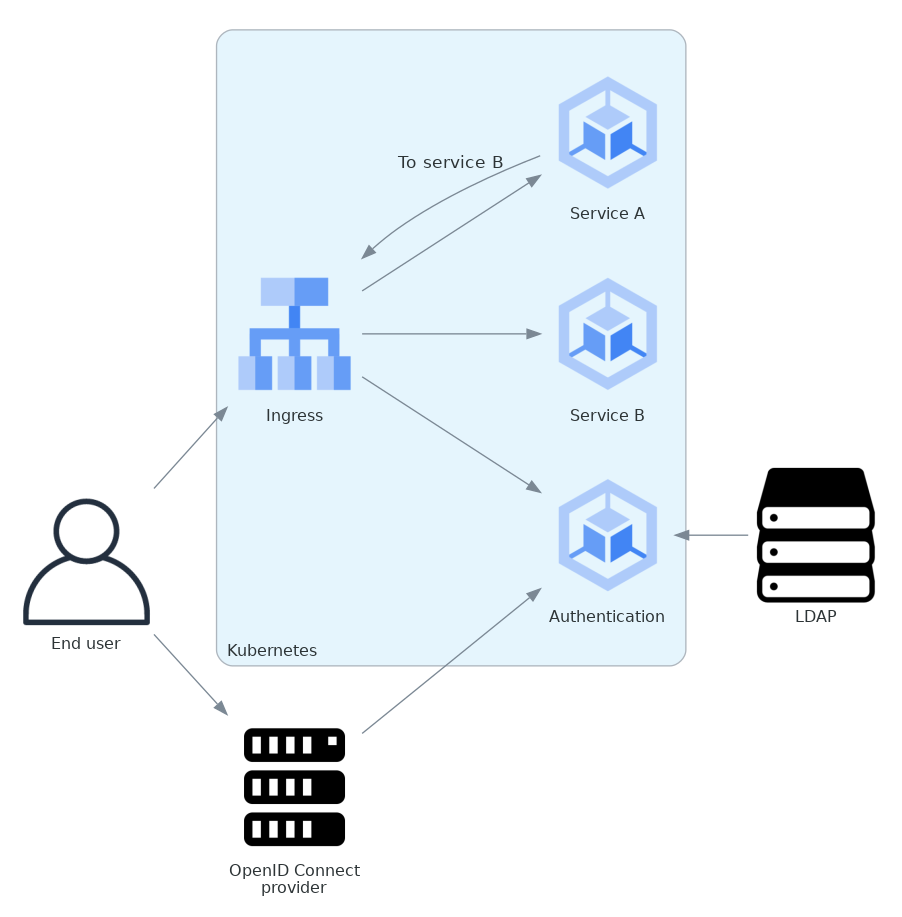
Both services receive user requests. Service A also sends requests to service B.
Security model#
The identity management system attempts to provide the following security services:
Incoming web requests will not be allowed through to the protected service unless they present valid authentication credentials.
Unauthenticated browser users will be sent to a configured identity provider and then returned to the service they are attempting to access after successful authentication.
Authentication credentials expire at a configurable interval, forcing reauthentication. As an exception, user tokens may be created without an expiration. This exception is not ideal from a security perspective, but the reduction in user hassle and documentation complexity is a worthwhile security trade-off.
Users may create (and delete) new tokens for use outside the browser, but the access granted by such tokens is limited to the access available to the user creating the token.
Tokens to act on behalf of the user are only issued to protected applications on request, are marked with the application to which they were issued, and can be restricted in scope.
Applications can restrict access to only delegated tokens issued to other services, without allowing access to the user directly. This is sometimes useful in a microservice architecture to separate components of a service into a lower-level service that should not be directly accessible.
Applications that are external to the Science Platform, or that need separate control over the authentication process, can use the identity management system as an OpenID Connect authentication provider.
Cross-site CORS preflight requests from outside the Science Platform are not allowed. Any requests that would trigger CORS preflight will only be allowed from web sites hosted inside the same Science Platform (and possibly not then, depending on the CORS policy of individual applications).
In providing those services, it attempts to maintain the following properties:
Authentication cookies are tamper-resistent. (However, they are still bearer cookies and can be copied and reused. See the discussion below.)
Authentication credentials delegated to Science Platform services are opaque and must be validated by the identity management system on each use. Revoking an authentication credential therefore takes immediate effect. There is no need for applications to maintain revocation lists, or for administrators to plan around revoked credentials still being valid through an expiration time.
The identity management system itself is hardened against common web security attacks, specifically session fixation on initial authentication, CSRF on token creation and deletion, cookie theft, and open redirects from the login and logout handlers.
Access to only the underlying storage for the authentication and authorization component does not allow the attacker to bypass authentication checks. The contents of the storage are protected by a key held by the authentication service and stored separately.
The identity management system does not attempt to protect against the following threats:
Web security vulnerabilities in the protected application. The identity management system only provides authentication gating. After authorization, the web request and response from the protected application are not modified and no additional security properties are added. (However, some facilities to assist the application with this may be added in the future. See DMTN-193 for more details.)
Compromise of the internal Kubernetes network of the Science Platform deployment. The identity management system does not require or support TLS or other network security measures inside the Kubernetes network. It assumes internal Kubernetes network traffic cannot be intercepted or tampered with.
Cookie or token theft. The identity management system relies on the security of the browser cookie cache and the security properties of HTTP cookies to protect its session cookie from theft. An attacker who is able to steal the cookie is able to impersonate the user from whom they stole the cookie. Similarly, the system issues bearer tokens on user request, and those tokens are sufficient for authentication. The identity management system does not protect against token mishandling or theft. This is not ideal, but doing something better requires security infrastructure for clients of the Rubin Science Platform that isn’t realistically available.
Compromise of internal secrets. If an attacker gains access to the Kubernetes secrets or the running pods for identity management system components, that attacker will be able to impersonate any user.
Manipulation of the underlying storage. The important information is encrypted and integrity-protected, but an attacker with direct storage access could trivially cause a denial of service by deleting user sessions and erase historic log data. The storage scheme only prevents an attacker with storage but not application access from creating tokens for arbitrary identities or modify existing tokens.
User identity#
Users of deployments that use federated identity will authenticate using their account at their local institution, or their choice of a cloud identity provider such as GitHub or Google. That institution will, in turn, release their identity to the Science Platform. This source of identity is discussed in detail in Federated identity.
The other two options are:
GitHub
Local identity provider supporting OpenID Connect
If GitHub is used as the identity provider, identity information will be taken from the user’s GitHub account information, and the user’s groups (see Groups) will be derived from the user’s organization and team memberships on GitHub. If a local identity provider is used, identity and group information will be read from an associated LDAP server.
In all cases, the user identity provider is also the primary source of user authentication. After a user has authenticated via their identity provider, they may create an authentication token for programmatic access to the Science Platform (see Token authentication). However, they must authenticate via their identity provider first.
The Science Platform will not store or verify any user authentication information, such as passwords, access codes, or certificates, apart from the tokens issued by the Science Platform after a successful authentication. This means the Science Platform is also not responsible for (and cannot assist with) lost passwords, credential resets, or other authentication support. Authentication is delegated to the identity provider and the Science Platform trusts the identity data provided by that provider.
Federated identity#
Addresses requirements DMS-LSP-REQ-0023 (Use of External Identity Providers) and DMS-LSP-REQ-0024 (Use of Mutliple Sets of Credentials).
Deployments of the Science Platform that use federated identity will support the InCommon federation. Other federations may also be supported.
A new user of a deployment using federated identity will go through an enrollment process. This process will gather the user’s identity information as released by their federated identity provider (name, email, and institutional affiliation), and allow the user to select a username for use with the Science Platform. Usernames will be unique across the Science Platform and must satisfy the requirements given in DMTN-225. If the user chooses, they can also specify a name and email address for the Science Platform to use in preference to the one released by their identity provider. The user will be required to verify that they can receive email at the email address they specify.
At the conclusion of enrollment, the user will have a pending account on that Science Platform but will not yet have access. The user must then be approved for access to the Science Platform. That approval process will place the user in an appropriate access group for their data rights, as determined by the approver. This decision will be taken according to Rubin Observatory policy based on institutional affiliation and possibly data obtained from outside the identity management system. Approvers will be project staff who have the knowledge and authority to verify the data rights of a particular community of users. Technical expertise in the identity management system is not required. Once the user is approved, their account will become active and they will be able to use it to access the Science Platform.
Once a user’s account is active, they may add additional identities to that same account. Those identities may be from other identity providers that are part of a supported identity federation, or cloud identity providers. GitHub and Google, in particular, will be supported as identity providers. All identities added to the same account are treated as equivalent for authentication purposes; the user can use any of the linked identity providers to authenticate to the Science Platform.
Note that users can use GitHub or Google as their authentication provider for initial enrollment, although in that case the identity provider will probably not release any information useful for determining their data rights, and the approver will therefore need information from outside the scope of the identity management system.
Once the user’s account is active, they can change their preferred name or email address whenever they wish. If they change their email address, they will have to verify that they can receive email at the new email address.
Tokens#
All authentication of browser or API access to the Science Platform except the identity management system is done with bearer tokens. These are short, random strings that function as lookup keys for active user authentication sessions.
The identity management system of a deployment using federated identity is a special case. It is only accessible via a web browser and uses identity information from the federated identity provider directly. Tokens cannot be used to access the identity management system.
Tokens come in six types. The uses of those token types are discussed in more detail in Authentication flows.
- session
Authenticates web access from a browser. This type of token is stored in the user’s browser as or inside an HTTP cookie, and is sent by that browser to the Science Platform when the user attempts to access a non-public page. See Browser authentication for more details.
- user
An authentication token created by the user. The user generally authenticates with a session token to create a user token. These tokens are intended for use in programmatic access to the Science Platform from user-written programs or local applications. See Token authentication for more details.
- internal
Used for service-to-service authentication when a service makes a subrequest to another service as part of fulfilling a user request. These tokens are associated with the identity of the user making the original request, but have restricted access permissions and are also associated with the service making the subrequest. See Subrequest authentication for more details.
- notebook
A special case of an internal token used by the Notebook Aspect. When a user spawns a Notebook Aspect lab, that lab is issued a token with all the same access rights as the user’s browser session. That token is then available to the user for API calls to other Science Platform services from within their notebook.
- oidc
An access token issued as a result of an OpenID Connect authentication. This token is used by the OpenID Connect client to retrieve metadata about the authenticated user from the identity management system.
- service
The one type of authentication token not associated with a user. These tokens are used when one service wants to make an API call to another Science Platform service that is unrelated to a user request. For example, a monitoring service may want to make a test API call to another service to ensure that it is operating properly. See Service-to-service authentication for more details.
These tokens tend to organize into hierarchies, as shown in the following diagrams.
graph TB
session
internal_a[internal]
internal_b[internal]
internal_c[internal]
internal_d[internal]
internal_e[internal]
internal_f[internal]
notebook_a[notebook]
notebook_b[notebook]
user_a[user]
user_b[user]
service
oidc
subgraph Session
direction LR
session --> notebook_a --> internal_a --> internal_f
session --> internal_b
session --> oidc
session --> user_a
end
subgraph User
direction LR
user_b --> internal_c
end
subgraph Service
direction LR
service --> internal_d
service --> notebook_b --> internal_e
end
Session ~~~ User ~~~ Service
Fig. 1 Token type hierarchy#
The token type on the left of each arrow is used as authentication to create the token type on the right of the arrow. Token creation other than creation of a user token from a session token happens automatically and the user need not be aware of it.
The session hierarchy starts from a user’s browser session. If the user accesses services that require authentication but don’t make any subrequests, no further tokens are created. Otherwise, notebook, oidc, and internal tokens may be created to satisfy the user’s requests. Notice that subrequests can themselves have subrequests, which may create a chain of internal tokens. The user can also manually create a user token.
The user hierarchy shows the user token being used to access services that make subrequests.
The service hierarchy is for service-to-service authentication outside the scope of a user request. Service-to-service authentication may also involve notebook and internal tokens.
Scopes#
Every token is associated with a set of scopes. These scopes are used to make authorization decisions. Each service or component of the Science Platform will require the authentication token have specific scopes to be allowed to access it. Requests authenticated with a token without the necessary scopes will be rejected with an error.
Scopes come originally from the user’s group membership. When they authenticate to the Science Platform with a web browser and get a session token, that token is given a list of scopes according to a per-deployment mapping of groups to scopes. Any subsequent notebook tokens created from that session token receive the same scopes. Internal tokens created from that token have at most the same scopes, usually fewer (since they will be restricted to only the scopes necessary for subrequests). The same is true of user tokens: they have at most the same scopes, but usually fewer. The user may choose which of the scopes in their session token they want to grant to a newly-created user token.
Scopes are used for “coarse-grained” access control: whether a user can access a specific component or API at all, or whether the user is allowed to access administrative interfaces for a service. “Fine-grained” access control decisions made by services, such as whether a user with general access to the service is able to run a specific query or access a specific image, are instead made based on the user’s group membership. See Groups for more details.
For a list of the scopes used by the Science Platform, their definitions, and the services to which they grant access, see DMTN-235.
Child tokens#
Notebook, internal, and oidc tokens are created from another token and are called “child tokens.” The token from which they are created is called a “parent token.”
Child tokens inherit their lifetime and scopes from their parent token, in a possibly restricted way. The child token will never have more scopes or a longer lifetime than the parent token, but may have fewer scopes or a shorter lifetime.
When a token is revoked, all child tokens of that token are also immediately revoked. This happens when the user logs out in their web browser (revoking the session token and all child tokens of the session token), or when the user deletes a previously-created user token (revoking all child tokens of that user token).
Although the user authenticates with a session token in order to create a user token, user tokens are not child tokens of the session token and have an independent lifetime. As discussed in Token authentication, user tokens may have a longer lifetime than the session token used to create them.
Authentication flows#
Addresses requirement DMS-LSP-REQ-0022 (Common Identity).
So far as possible, authentication and access control for Science Platform services will be handled by a separate authentication service interposed between the user request and the service backend. Service backends need only be aware of information exposed by the authentication service, not the precise mechanism the user used to authenticate.
The Science Platform requires Kubernetes, which handles this type of interposition via Ingress resources.
If the authentication service rejects the request at the ingress, it is never passed to the backend service.
The details of required authentication and authorization are configured in a Kubernetes custom resource, which in turn is used to generate an Ingress resource with correct authentication and authorization configuration.
One implication of this is that all access to services in the Science Platform, including access to services from the Notebook Aspect and service-to-service access, must go through the ingress.
This is not the default in Kubernetes; by default, applications running within the same Kubernetes cluster can access the Service or even Pod of another service directly without using the ingress.
Correct use of the authentication service therefore requires blocking non-ingress access to other services via, for example, a Kubernetes NetworkPolicy.
TLS is required for all traffic between the user and the Science Platform. (See requirement DMS-LSP-REQ-0026, Using Secure Protocols.) Communications internal to the Science Platform need not use TLS provided that they happen only within a restricted private network specific to that Science Platform deployment.
Use cases#
Here are some typical authentication use cases. This is a sampling of typical uses, not a comprehensive list of possibilities.
User authenticates using an identity provider and obtains a session token.
User accesses a service using a web browser. The scopes of the user’s session token are checked to ensure the user has the required scope to access that service.
User spawns a notebook via the Notebook Aspect. The notebook spawner requests a delegated notebook token. A new notebook token is created as a subtoken of the session token and made available to the notebook spawner. The notebook spawner arranges to make that token available to the spawned notebook server.
User makes a request via a web interface that requires talking to another backend service. The web service requests an internal token with appropriate scope in its ingress configuration. The web service receives that token from the request and uses it to make requests on behalf of the user. This may repeat recursively if that backend service needs to make requests to another service. The backend service may restrict access to only other services and not allow direct access from users.
User makes a request via an API from their notebook server. The notebook token is used for this request.
User makes a request via an API from the notebook server that requires making subrequests on the user’s behalf. This follows the same pattern as the equivalent case with a web UI: the backend service requests a subtoken and uses it.
User goes to the token management page and creates a user token. The user chooses the scopes to grant that token (from the scopes the user’s session token has), its name, and when it will expire. This user token is created as a new token, not as a subtoken of the session token, but inherits information from the session token. User stores that token locally on their laptop and uses it to make a request to an API service. The token is checked to ensure that it has the appropriate scope for access to that service.
User makes an API call with their user token that requires making subrequests to other services. This proceeds as with web UIs and notebook API calls.
A service requests a token for itself, unrelated to any user request. That token is created and provided to the service. The service then uses that token to make API calls to other services within the same Science Platform deployment.
A service uses a service token with
admin:tokenscope to create a newservicetoken for an arbitrary user. The service can then use that token to authenticate as a user to other services. This flow might be used by a load-testing or monitoring application.An IDAC wants to authenticate a user and determine their data access rights. See DMTN-253.
Browser authentication#
If a user goes to a Science Platform web page without currently being authenticated, they will be sent to a login provider to authenticate. This may be a federated login provider that will allow them to choose their federated identity provider (or will remember their previous selection if desired and automatically send them there). Alternately, it could be GitHub or a local OpenID Connect provider.
The Science Platform authentication system will perform an OpenID Connect or (for GitHub only) OAuth 2.0 authentication with the login provider and use that to obtain the user’s identity. It will then obtain any other needed information about the user (numeric UID, primary GID, group membership and numeric GIDs, full name, email address, etc.) following the rules for sources of user information defined in DMTN-225. From that information, a session token will be created with scopes based on the user’s group membership. That session token will be stored in the user’s browser, restricted to that installation of the Science Platform. Then, the user will be redirected back to the page they were attempting to visit, now with authentication.
As a special case, if the user is accessing the identity management system of a deployment of the Science Platform using federated identity, no session token is created or used. The OpenID Connect authentication is used directly to authenticate access to the identity management system.
The session token stored in the browser will expire periodically, forcing the user to reauthenticate, so that stolen browser credentials cannot be reused indefinitely. The user’s scopes are calculated based on their current group membership at the time of authentication. The user can also log out at any time, which revokes their session token, revokes any child tokens (notebook or internal, but not user) created from that session token, and forces reauthentication the next time they attempt to visit a page that requires authentication.
The user’s cookie holding their session token should not be passed down to individual Science Platform applications in a way that would allow that application to impersonate the user to different applications. This is handled by filtering those headers out of the HTTP request in the Kubernetes ingress. See DMTN-193 for more details.
Token authentication#
Users can create user tokens and manage them (modify their names, scopes, and expiration, delete them, and see their history) via a web UI provided by the Science Platform. These tokens are specific to that deployment of the Science Platform. User tokens are intended for non-browser access to the Science Platform, such as for API calls from programs, use in astronomy desktop applications, and so forth.
User tokens have a public component (used as a unique identifier for the token in the UI) and a secret component. The full token including the secret component is shown only when the token is created and subsequently cannot be obtained again.
The user chooses a name for the user token when creating it. This name must be unique across all non-deleted user tokens for that user, and is intended as an aid for the user to keep track of where the token is being used.
When the user creates a user token, they can choose which scopes to delegate to that token. They can only delegate scopes that their current session token has. The user may wish to only delegate a subset of scopes so that, for example, the user token cannot be used to create more user tokens or access more privileged APIs unrelated to the purpose for which the token is being created.
When the user creates a user token, they can set an expiration date for the token. They can also set the token to never expire.
The metadata associated with a user token (full name, email address, numeric UID, group membership, and so forth) will be the same as the user who created it.
To authenticate with a user token, the user provides it in the Authorization header.
The preferred way of doing so is as an RFC 6750 bearer token.
However, some astronomy applications may only support HTTP Basic Authentication (RFC 7617), so it is supported as an alternative to the bearer token protocol.
The token can be put in either the username or password field, and the other field is ignored.
User tokens cannot be used to access the identity management system to attach new federated identities, change the user’s email address, change group memberships, or make any similar changes. They may only be used to access Science Platform services.
Subrequest authentication#
In some cases, a Science Platform service will need to perform further requests on behalf of a user in order to satisfy a request. For example, the Portal Aspect will need to make TAP queries on the user’s behalf.
Each of these requests should be authenticated and authorized as the user, so that the underlying services do not need to perform separate authorization checks. Instead, the same authentication service that is interposed for user requests should also be interposed to perform access control for each subrequest. This, in turn, implies that services should be able to obtain tokens that they can use to make subrequests.
These tokens, however, should not be the same as the token that the user used to authenticate the initial request, since that token will often have all the scopes that a user has and would be able to perform far more actions than the service should be able to perform on behalf of the user. For example, the Portal Aspect should not be able to create a notebook as the user in the Notebook Aspect. The user’s original token (session or user) may also have a long expiration time or may not expire at all, whereas the service only needs a token for long enough to satisfy the user’s request.
Services therefore have a mechanism to request delegated tokens. These come in two types: internal tokens and notebook tokens.
If a server is so configured, the authentication system will issue a new internal or notebook token for that service (or reuse an existing one if appropriate). For internal tokens, this will be limited in scope to only the permissions that service needs and with an expiration time set. The service will receive this new token as part of the request, in an HTTP header, and can then use the token to make subsequent subrequests required to respond to the user’s request. The lifetime of this token will be capped at the lifetime of the parent token on which it’s based.
As a special case, the Notebook Aspect of the Science Platform is intended as a general-purpose computing platform for the user and should have all of the same access that the user themselves have. The Notebook Aspect (and only it) will therefore get a notebook token rather than an internal token. This is a special case of an internal token that has all of the same scopes as the user’s original session token, and is associated with the user’s notebook server. It may have a lifetime limited to the lifetime of the user’s notebook server.
Services that know they may need to use the token for some period of time (for long-running operations, for example) can request that the token have a minimum remaining lifetime. Since the lifetime of the delegated token can be no longer than the lifetime of its parent token, this may force the user to reauthenticate before accessing the service if their token does not have sufficient remaining lifetime.
Authorization headers used for token authentication are filtered out of the request so that they are not passed down to the underlying Science Platform service.
This prevents services could recover the user’s original token from the HTTP headers of the request.
Services may limit access to only other named services and prohibit direct access from the user, even if the user’s authentication token has the required scopes. This pattern is used to implement supporting services that should only receive calls from other services, and where direct access by users may create security concerns. See SQR-096 for an example of such a service.
Service-to-service authentication#
In some cases, services may need to access other Science Platform services on their own behalf, unrelated to a user request. For example, a monitoring system may need to make periodic requests to authenticated APIs of Science Platform services to ensure that they are running and correctly responding to requests.
These requests will be authorized in the same way as subrequests discussed above, by interposing the same authentication system used for user requests. They are authenticated with service tokens, which are issued only to services and are never used by users.
Services can ask for service tokens by creating a custom Kubernetes resource specifying the properties of the service token, including the identity of the service and the scopes it requires.
The authentication service will then provide that service token as a Kubernetes Secret resource associated with the request in the custom resource, and thereby make it available to the service pods through the normal Kubernetes mechanisms for injecting secrets into pods.
The authentication service will also automatically refresh the service token to ensure that it does not expire.
As specified in DMTN-225, the usernames associated with all such tokens must begin with bot-.
OpenID Connect authentication#
Some Science Platform deployments run third-party services (Chronograf, for example) that themselves want to do OpenID Connect authentication of the user. To support those services, the authentication service of the Science Platform is also an OpenID Connect provider. Such services can therefore point to the authentication service as the authentication provider, and those authentications will use the same source of identity as other authentications to the Science Platform. (This authentication is independent of any use of OpenID Connect by the authentication service to a federated or local identity provider external to the Science Platform, although the two authentications will be chained together when needed.)
IDACs may also wish to rely on the USDAC for user authentication and data rights verification. In this mode, they would act as OpenID Connect clients of the USDAC.
All OpenID Connect clients must be pre-registered with Gafaelfawr on the instance of the Science Platform that they wish to use for authentication and use a return URL and client ID and secret that match their registration.
OpenID Connect authentication used in this fashion does not do any access control. All users with any access to that Science Platform deployment will be able to complete the OpenID Connect authentication. The protected service must do any necessary access control itself.
The ID token returned by this OpenID Connect provider is a JWT (see RFC 7519).
The standard scopes openid (required), profile, and email are supported, as well as the non-standard rubin OpenID Connect scope.
If the rubin scope is requested, the resulting ID token will include a data_rights claim that contains a space-separated list of data releases to which the user has access.
This list is determined based on the user’s group membership.
For more details, see DMTN-253.
This ID token is not a token as defined by Tokens and cannot be used to authenticate to any other Science Platform service. It is an implementation detail of the OpenID Connect authentication process.
The access token returned by an OpenID Connect authentication is a regular token as defined by Tokens, of type oidc. It is a child token of the session token that the user uses to complete the OpenID Connect authentication. It has no scopes and can only be used to obtain claims about the user, normally via an OpenID Connect userinfo request. These claims mirror the claims include in the ID token, but may contain more information if the OpenID Connect client didn’t request all possible OpenID Connect ID token scopes.
Groups#
As discussed in Scopes, when a user authenticates to the Science Platform with a web browser, their group membership is retrieved and they are granted scopes based on their group membership. The group membership of the user is also provided to each service in an HTTP header, and is available via the Token API on request from any service receiving a delegated token (see Subrequest authentication). Finally, groups are used to determine the user’s data rights as included in OpenID Connect ID tokens (see OpenID Connect authentication).
The source of the user’s group membership information varies by type of Science Platform deployment.
For deployments using GitHub, group membership is taken from the user’s GitHub teams. For deployments using a local identity provider, group membership comes either from a local LDAP server or from the token issued by an OpenID Connect authentication service.
For deployments using federated identity, group membership is maintained in the identity management system. Users will be added to appropriate access groups during enrollment by the approver. Users may also create their own groups, and add and remove members from those groups as they see fit. Collaborations using the Science Platform may also maintain groups of their members or affiliates.
For further details about the sources of group information and their naming constraints, see DMTN-225.
User private groups#
In addition to those groups, in federated identity deployments every user will also be a member of a group with the same name as their username. That group will have only one member, the matching user, and it will be the user’s primary GID. (This is commonly called a user private group.) This allows services that make access decisions based on groups to uniformly use group membership for all access decisions, without having to special-case access rules for individual users. It also provides the user with a default group for services that use an underlying POSIX file system, such as the Notebook Aspect.
GitHub deployments also use user private groups with the same GID as the user’s UID. Local OpenID Connect deployments must provide a primary GID for each user, but that GID may or may not be for a user private group.
Access control based on groups#
Access control decisions based on group membership must be made by individual services. The authentication service only applies access restrictions based on scopes, and otherwise passes the group information to the service for it to do with as it sees fit. In many cases, services will make subrequests on behalf of the user, and rely on access control by group membership to be imposed by lower-level services.
For applications that use IVOA-standard protocols for astronomy, the identity management system provides an IVOA Group Membership Service Version 1.0 implementation. Service with a delegated token for a user can query that service for the user’s group membership.
UIDs and GIDs#
Portions of the Science Platform, particularly the Notebook Aspect, will use an underlying POSIX file system. Users therefore need numeric UIDs and GIDs to access those portions of the Science Platform, since those will be used for access control in the POSIX file system.
Every user is must be assigned a numeric UID and primary GID, and every group is assigned a numeric GID.
For deployments using federated identity, UIDs and GIDs are assigned and recorded inside the identity management system. The primary GID for a user will be equal to the UID and will correspond to the GID for the user private group.
For deployments using GitHub, UIDs and GIDs come from GitHub. A user private group with a GID matching that UID will be synthesized and added to the user’s group membership.
For deployments using a local identity management system, that system must provide the UIDs and GIDs for the user and their groups, either via LDAP or from an OpenID Connect ID token.
For further details on UID and GID assignment, see DMTN-225.
Identities used for service-to-service authentication internal to a deployment exceptionally may not have UIDs or GIDs if they don’t need to authenticate to services that require them.
Origins and domains#
The identity management system can be run in one of two modes: all protected services share the same domain name, or protected services may use subdomains of the parent domain managed by the identity management system. The latter configuration preferred for production deployments since it allows components of the Science Platform to be isolated from each other on different JavaScript origins. This is the recommended configuration for per-user JupyterLab servers, for example. (See DMTN-193.)
If the identity management system is configured to allow subdomains, it will use domain-scoped authentication cookies instead of host-scoped cookies. This means the authentication cookie will be sent to any web server hosted at a subdomain of the root domain of the Science Platform. In this configuration, security guarantees can only be maintained if every extant subdomain points to the same instance of the Science Platform and is managed by the same deployment of the identity management system.
CORS#
The identity management system also intercepts and examines all CORS preflight requests and implements a global minimum CORS policy.
Preflight requests from an Origin outside of that instance of the Science Platform are always rejected.
This ensures that, regardless of the CORS policy implemented by the underlying application, cross-site requests that require CORS preflight checks will not be accepted from outside the Science Platform.
If the request comes from within the Science Platform, such as from a subdomain of the base domain, it will be passed through to the protected service, which can then impose its own CORS policy. Therefore, cross-site requests that require CORS preflight will be approved only if they come from within the Science Platform and the underlying service accepts the CORS preflight request.
Quotas#
Partly addresses requirements DMS-PRTL-REQ-0117 (Computational Quotas User Interface) and DMS-NB-REQ-0022 (Computational and Storage Quotas.
The identity management system is responsible for calculating user quotas and providing user quota information to the rest of the Science Platform. It also provides a simple implementation of API quotas and rate limiting that any Science Platform service can use, although that implementation has some restrictions and may not be suitable for all API quotas.
Quota calculation#
There are three sources of quota information for a given user:
Default quotas for all users of a given instance of the Science Platform.
Additional quota granted to members of specific groups, which is added to the quota available to all users.
Temporary quota overrides that are added by Science Platform administrators to handle urgent problems, such as an overloaded infrastructure.
The identity management system is responsible for calculating quota for each user by combining those three sources of quota and making that quota information available to the user, to administrators, and to services that need it.
In addition, the identity management system supports disabling quotas completely for members of certain groups, allowing (for example) Science Platform administrators to access services without regard to quota.
API rate limiting#
Because the authorization portion of the identity management system has to intercept requests to ensure that they are allowed, it is also in a position to impose rate limits. It therefore supports a simple rate limiting system that can be used by any service that does not have more complex needs.
API quotas for this system are expressed as an allowed number of requests per some interval of time. Requests are counted when they are authorized, and the identity management service rejects requests that exceed the API quota, along with an appropriate HTTP status code and headers to tell the user when API requests will be permitted again.
This mechanism has the serious limitation that it does not know the nature of the request and therefore treats all requests as equivalent for quota purposes, even if one request is a cheap informational API call and another request is an expensive data retrieval. It is therefore only suitable for rate limiting of services where this limitation is acceptable. More complex quota enforcement will need to be done by the service itself, based on quota information retrieved from the identity management system, so that the service can apply appropriate restrictions based on the impact of the request.
Token API#
All actions on tokens — issuing them, revoking them, modifying them, retrieving their associated data, retrieving their history, and so forth — may be done through a token REST API.
Authentication to that REST API is via either cookie or bearer token in an Authorization header, the same as any other Science Platform API.
The browser-based user interface for creating and manipulating user tokens described in Token authentication is implemented on top of that REST API.
Any user authenticated with a token having user:token scope (given to all session tokens by default, but often not delegated to user tokens) can list, create, revoke, and see the history for their own tokens.
Anyone in possession of a token can get the data associated with that token (its scopes, expiration, and so forth) and the identity data for the user associated with that token (full name if known, email address, UID, group membership, and so forth) via the token API by authenticating with that token.
This can be used by services making or processing subrequests (see Subrequest authentication).
Administrators with a token having admin:token scope can take all of those same actions on behalf of the user; can add, remove, or list administrators (whose session tokens receive the admin:token scope when they authenticate); can create new tokens on behalf of arbitrary users or modify arbitrary user tokens; and can do global queries on all tokens, token history, and any other data stored by the authentication service.
Administrators cannot get the secret portion of existing tokens without having possession of the token.
Administrators with a token having admin:userinfo scope can request user information about arbitrary users without having a token for that user.
These APIs only work for deployments that use LDAP as the source for user information and are not implemented on deployments that use GitHub.
References#
- DMTN-193
Discussion of web security for the Science Platform. This is primarily about implementation details, but the designs here for filtering some request headers and for using multiple domains for Science Platform services to limit the possible damage from credential leakage are relevant to the overall design.
- DMTN-224
The implementation details of the Science Platform identity management system.
- DMTN-225
Metadata gathered and stored for each user, including constraints such as valid username and group name patterns and UID and GID ranges.
- DMTN-235
Lists and defines the scopes used by the Science Platform.
- DMTN-253
Documents how IDACs can authenticate users via OpenID Connect. This includes more detailed documentation of the features of the Science Platform OpenID Connect authentication service.
- LDM-554
General requirements document for the Science Platform. This includes some requirements for the identity management system.
- RDO-013
The Vera C. Rubin Observatory Data Policy, which defines who will have access to Rubin Observatory data.
- SQR-069
History and analysis of the decisions made during design and implementation of the Science Platform identity management system.
The references section of DMTN-224 has a more complete list of tech notes related to RSP identity management, including historical and implementation tech notes.